In this vignette we explain the numerical scheme used in mizer. We will not go into the details of the model itself, which is described in the model description vignette. We will focus on how the model is discretised and how the resulting difference equations are solved.
The weight grid
The model dynamics are described by partial differential equations (PDEs) for the consumer number density \(N(w)\) of each species and the resource number density \(N_R(w)\). These depend on the individual weight \(w\). To solve these equations numerically, we discretise the weight axis. In this vignette we suppress the species index and write the equations for one species; the same scheme is applied to each species.
We choose a grid of weights \(w_1, w_2, \ldots, w_K\). The grid is logarithmically spaced, meaning that the ratio of consecutive weights is constant: \[ w_{j+1} / w_j = 10^{\Delta x} = \text{const}. \tag{1}\] The logarithmic spacing is chosen because the weights of fish span many orders of magnitude, from milligrams to megagrams.
This grid defines a set of bins. The \(j\)-th bin is the interval \([w_j, w_{j+1})\). The width of the \(j\)-th bin is \[ \Delta w_j = w_{j+1} - w_j = w_j (10^{\Delta x} - 1). \tag{2}\] Note that \(\Delta w_j\) increases with \(w_j\), which is appropriate for a logarithmic grid.
In the finite-volume scheme used by mizer, the discrete value \(N_j\) represents the average of the number density \(N(w)\) over the \(j\)-th bin, \[ N_j = \frac{1}{\Delta w_j} \int_{w_j}^{w_{j+1}} N(w)\, dw, \tag{3}\] so that the number of individuals in the \(j\)-th bin is exactly \(N_j \Delta w_j\). Note that \(N_j\) is the bin average, not the point value of the density at the bin boundary \(w_j\). For a smooth density the bin average equals the value at the bin centre \[ w_j^c = \sqrt{w_j\,w_{j+1}} \tag{4}\] to second order in the bin width; \(w_j^c\) is the midpoint of the bin on the logarithmic axis. We will need this when we discretise the diffusion.
(In the finite-volume literature the bins are usually called cells and the bin boundaries cell faces; we keep the size-spectrum terminology “bin” and “bin boundary” throughout.)
The Transport Equation
The time evolution of the number density \(N(w)\) is described by the McKendrick-von Foerster equation with an added diffusion term: \[
\frac{\partial N}{\partial t} + \frac{\partial}{\partial w} \left( g N - \frac{1}{2}\frac{\partial(d N)}{\partial w} \right) = -\mu N
\tag{5}\] where \(g(w)\) is the somatic growth rate, \(d(w)\) is the diffusion coefficient and \(\mu(w)\) is the total mortality rate.
We discretise this equation using a finite-volume scheme. The three rates enter the equation in two structurally different ways, and this dictates how we represent them on the grid (the Point values and bin averages section explains why):
- the growth rate \(g\) is a velocity at the bin boundaries, so we use its point value there, \(g_j = g(w_j)\);
- the diffusion coefficient \(d\) and the mortality rate \(\mu\) are properties of a whole bin, so we use their bin averages \(d_j\) and \(\mu_j\) (each equal to the value at the bin centre \(w_j^c\) to second order).
Discretisation of the Fluxes
The term inside the derivative with respect to \(w\) is the flux \(J(w)\): \[ J(w) = g(w) N(w) - \frac{1}{2}\frac{\partial(d(w) N(w))}{\partial w} \tag{6}\] We consider the \(j\)-th size bin \([w_j, w_{j+1}]\). Integrating the conservation equation over this bin gives: \[ \int_{w_j}^{w_{j+1}} \frac{\partial N_j}{\partial t}dw + J(w_{j+1}) - J(w_j) = -\int_{w_j}^{w_{j+1}} \mu(w) N(w) dw \tag{7}\] Approximating the integral and dividing by \(\Delta w_j\): \[ \frac{\partial N_j}{\partial t}+ \frac{J_{j+1} - J_j}{\Delta w_j} = -\mu_j N_j \tag{8}\] where \(J_j\) represents the flux at the boundary \(w_j\).
Advective flux
The advective flux \(gN\) at the bin boundary \(w_j\) is the growth velocity there, \(g_j\), times the density there. The density at the boundary must be reconstructed from the bin averages \(N_{j-1}\) and \(N_j\) of the two adjacent bins. The simplest reconstruction is upwind: because fish grow towards larger sizes (\(g > 0\)), take the value from the bin below, \[ J_j^{adv} = g_j\, N_{j-1}. \tag{9}\] This is only first-order accurate, because it uses a bin-centre value (\(N_{j-1}\), the average of bin \(j-1\)) at the boundary, which is half a bin away; the second-order reconstruction is the subject of Section 13. (For \(j=j_{min}\) this boundary flux is the recruitment \(R_{dd}\).)
Diffusive flux
The diffusive flux \(-\frac{1}{2}\frac{\partial(d N)}{\partial w}\) at the boundary \(w_j\) is the derivative of the product \(dN\). We evaluate that product at the two adjacent bin centres — where the bin averages \(d_{j-1}N_{j-1}\) and \(d_j N_j\) live — and take a central difference across the boundary: \[ J_j^{diff} = -\frac{1}{2}\,\frac{d_j N_j - d_{j-1} N_{j-1}}{w_j^c - w_{j-1}^c}. \tag{10}\] Because the boundary \(w_j\) is the midpoint (on the logarithmic axis) of the two bin centres \(w_{j-1}^c\) and \(w_j^c\), this central difference is a genuinely second-order approximation of the derivative at \(w_j\). Note that the diffusion coefficient enters only inside the product \(dN\): it is sampled at the bin centres, co-located with \(N_j\), and never separately at the boundary. This is why \(d_j\) is a bin average, not a bin-boundary point value like \(g_j\).
The total flux at boundary \(w_j\) is therefore \[ J_j = g_j N_{j-1} - \frac{1}{2} \frac{d_j N_j - d_{j-1} N_{j-1}}{w_j^c - w_{j-1}^c}, \tag{11}\] and similarly at boundary \(w_{j+1}\), \[ J_{j+1} = g_{j+1} N_j - \frac{1}{2} \frac{d_{j+1} N_{j+1} - d_j N_j}{w_{j+1}^c - w_j^c}. \tag{12}\]
Point values and bin averages
A size-dependent rate is represented on the grid as either a bin-boundary point value or a bin average, and which one is correct depends on how the rate enters the equations, not on the rate itself. Almost every rate is a bin average; the growth velocity is the one exception.
The growth velocity is a bin-boundary point value. Growth is an advection of mass through size, and the advective flux \(J_j^{adv}=g_j\,N(w_j)\) is the velocity at the boundary \(w_j\) times the density carried through it. The factor that belongs to the boundary is the velocity, so \(g_j = g(w_j)\) is the point value there. (The density at the boundary is a separate matter — it is reconstructed from the neighbouring bin averages, Equation 9.)
The diffusion coefficient is a bin average. It is tempting to treat \(d\) like \(g\), but \(d\) does not multiply a density at the boundary. It appears only inside the differentiated product \(dN\) (Equation 10), which we sample where the density lives — at the bin centres — and then difference across the boundary. So \(d_j\) is co-located with \(N_j\) and is a bin average, the value at the bin centre \(w_j^c\). It is needed inside the bin, not on the boundary.
Rates integrated against the density over a bin are bin averages. The mortality term is, exactly, \[ \frac{1}{\Delta w_j}\int_{w_j}^{w_{j+1}} \mu(w)\,N(w)\,dw. \tag{13}\] Because \(N_j\) is the bin average, the consistent way to factor this is \(\mu_j\,N_j\) with the bin-averaged mortality \[ \mu_j = \frac{1}{\Delta w_j}\int_{w_j}^{w_{j+1}} \mu(w)\,dw, \tag{14}\] since \(\int_{w_j}^{w_{j+1}}(N-N_j)\,dw = 0\) makes the leading error cancel and leaves an \(O(\Delta w_j^2)\) remainder. Using the point value \(\mu(w_j)\) at the left bin boundary instead is the lower-order choice. The same applies to every rate that enters inside an integral weighted by the abundance: the fishing-mortality contribution \(\int Q\,S(w)\,\text{effort}\,N\,dw\), the reproductive investment \(\int \psi(w)\,E_r(w)\,N\,dw\), and the predation and encounter convolutions integrated against \(N\) (see the FFT vignette). Each size-dependent factor is replaced by its bin average.
The energy income \(e(w)\) feeds both roles. It is the one quantity that sits on both sides of the distinction. Through the somatic growth rate \(g = e - e_r\) it supplies the growth velocity, wanted as a point value at the boundary \(w_j\). Through the reproduction integral \(\int \psi\,e\,N\,dw\) it is an integrand, wanted as a bin average (of the product \(\psi e\)). The same pointwise \(e(w)\) is therefore used as a point value for growth and bin-averaged only at its reproduction use-site; it must not be pre-averaged, or the growth velocity would be evaluated in the wrong place.
In summary:
| \(g\) |
growth velocity at the bin boundary |
point value at \(w_j\)
|
|
\(d\), \(\mu\); fishing/reproductive investments; predation and encounter integrands |
bin properties (a coefficient inside \(\partial(dN)/\partial w\), or a rate integrated against \(N\) over a bin) |
bin average over \([w_j, w_{j+1}]\)
|
|
\(e\) (energy income) |
both: growth velocity and reproduction integrand |
point value for growth; bin-averaged product \(\psi e\) for reproduction |
Plotting follows the same distinction. A bin average \(N_j\) does not live at the bin boundary \(w_j\) but at the geometric bin centre \(w^*_j=\sqrt{w_j\,w_{j+1}}=w_j\sqrt\beta\) (the log-midpoint, exact for the community spectrum \(N\propto w^{-2}\)). So under second-order bin-averaging mizer draws bin-averaged quantities (the abundance and the mortality/reproduction sinks) at \(w^*_j\) — a uniform half-bin shift to the right on the log axis — while point-valued quantities (the encounter and growth-type rates) stay on the nodes \(w_j\). The size-resolved array classes carry a representation tag recording which a quantity is, and the shift is applied only when second_order_w[["bin_average"]] is set, so default plots are unchanged.
Plotting follows the same distinction. A bin average \(N_j\) does not live at the bin boundary \(w_j\) but at the geometric bin centre \(w^*_j=\sqrt{w_j\,w_{j+1}}=w_j\sqrt\beta\) (the log-midpoint, exact for the community spectrum \(N\propto w^{-2}\)). So under second-order bin-averaging mizer draws bin-averaged quantities (the abundance and the mortality/reproduction sinks) at \(w^*_j\) — a uniform half-bin shift to the right on the log axis — while point-valued quantities (the encounter and growth-type rates) stay on the nodes \(w_j\). The size-resolved array classes carry a representation tag recording which a quantity is, and the shift is applied only when second_order_w[["bin_average"]] is set, so default plots are unchanged.
For the power-weighted spectrum plots (plotSpectra() and friends) the \(w^{\text{power}}\) factor must be evaluated where the density value lives, so it too is taken at the bin centre: each marker is the point \(\bigl(w^*_j,\,N_j\,(w^*_j)^{\text{power}}\bigr)\) on the continuous \(N(w)\,w^{\text{power}}\) curve. (Sampling the weight at the edge would mis-scale it by a factor \(\beta^{\text{power}/2}\), largest for the common \(\text{power}=2\) Sheldon plot.) A cumulative plot (plotCDF()) is the opposite case: a CDF value is cumulative up to a size, a boundary quantity, so its increments use the bin-averaged (centre-weighted) density but the cumulative is plotted on the bin edges, not the centres. Because the cumulative sum is inclusive — the sum through bin \(k\) is the integral over all bins up to and including bin \(k\) — each cumulative value is placed on that bin’s upper edge \(w_k+\Delta w_k\) (in both the default and second-order schemes). This makes the inclusive convention explicit and removes a one-bin offset that would otherwise leave the CDF only first-order accurate in its placement.
Semi-Implicit Time Discretisation
With the diffusion term, an explicit time discretisation would require a very small time step for stability (\(\Delta t \sim \Delta w^2\)). Therefore, we use a semi-implicit scheme where the densities \(N\) are evaluated at time \(t+1\), but the rates (\(g\), \(\mu\), \(d\)) are evaluated at time \(t\). Using a fully implicit scheme would require solving a nonlinear system at each time step, which is more computationally expensive. Thus, the discretised equation becomes: \[
\frac{N_j^{t+1} - N_j^t}{\Delta t} + \frac{1}{\Delta w_j} \left( J_{j+1}^{t+1} - J_j^{t+1} \right) = -\mu_j N_j^{t+1}
\tag{15}\] where the fluxes \(J_j^{t+1}\) are calculated using the densities at time \(t+1\) but the rates at time \(t\). To simplify the notation we will drop the explicit time indices on the rates, but it is important to remember that they are evaluated at time \(t\). Writing \(\Delta w_j^c = w_{j+1}^c - w_j^c\) for the spacing between adjacent bin centres, the fluxes at time \(t+1\) are: \[
\begin{aligned}
J_{j+1}^{t+1} &= g_{j+1} N_j^{t+1} - \frac{1}{2} \frac{d_{j+1} N_{j+1}^{t+1} - d_j N_j^{t+1}}{\Delta w_j^c} \\
J_j^{t+1} &= g_j N_{j-1}^{t+1} - \frac{1}{2} \frac{d_j N_j^{t+1} - d_{j-1} N_{j-1}^{t+1}}{\Delta w_{j-1}^c}.
\end{aligned}
\tag{16}\] This leads to a linear system of the form: \[
A_j N_{j-1}^{t+1} + B_j N_j^{t+1} + C_j N_{j+1}^{t+1} = S_j
\tag{17}\] where \(S_j = N_j^t\). This is a tridiagonal system for each species, which can be solved efficiently (e.g., using the Thomas algorithm).
The coefficients are: \[
\begin{aligned}
A_j &= -\frac{\Delta t}{\Delta w_j} \left( g_j + \frac{1}{2} \frac{d_{j-1}}{\Delta w_{j-1}^c} \right) \\
C_j &= -\frac{\Delta t}{\Delta w_j} \left( \frac{1}{2} \frac{d_{j+1}}{\Delta w_j^c} \right) \\
B_j &= 1 + \Delta t \mu_j + \frac{\Delta t}{\Delta w_j} \left( g_{j+1} + \frac{1}{2} \frac{d_j}{\Delta w_j^c} + \frac{1}{2} \frac{d_j}{\Delta w_{j-1}^c} \right)
\end{aligned}
\tag{18}\] The advective velocity is taken at each bin boundary (\(g_j\) at the lower boundary of bin \(j\), \(g_{j+1}\) at the upper one), and the diffusion differences the bin-averaged products \(d_jN_j\) between bin centres — exactly Equation 16.
Boundary Conditions
At the smallest size (\(j=j_{min}\)): The flux entering the grid is determined by recruitment: \[ J_{j_{min}}^{t+1} = R_{dd} \tag{19}\] (We assume diffusive flux at the lower boundary is negligible or incorporated into \(R_{dd}\)). The equation for the first bin becomes: \[ \frac{N_{j_{min}}^{t+1} - N_{j_{min}}^t}{\Delta t} + \frac{J_{j_{min}+1}^{t+1} - R_{dd}}{\Delta w_{j_{min}}} = -\mu_{j_{min}} N_{j_{min}}^{t+1} \tag{20}\] This involves \(N_{j_{min}}^{t+1}\) and \(N_{j_{min}+1}^{t+1}\). Comparing this to the general discretised equation translates to modifying the first row (\(j=j_{min}\)) of our tri-diagonal matrices:
- The \(j_{min}-1\) term does not exist, so \(A_{j_{min}} = 0\).
- The upward diffusion term from below the boundary is omitted, so \(B_{j_{min}}\) does not have the \(\frac{1}{2} \frac{d_{j_{min}}}{\Delta w_{j_{min}-1}^c}\) component: \[ B_{j_{min}} = 1 + \Delta t \mu_{j_{min}} + \frac{\Delta t}{\Delta w_{j_{min}}} \left( g_{j_{min}+1} + \frac{1}{2} \frac{d_{j_{min}}}{\Delta w_{j_{min}}^c} \right) \tag{21}\]
- The coefficient \(C_{j_{min}}\) remains unchanged from the general formula.
- The recruitment flux enters as a source term, so it is added to the right-hand side \(S_{j_{min}}\): \[ S_{j_{min}} = N_{j_{min}}^t + \frac{\Delta t}{\Delta w_{j_{min}}} R_{dd} \tag{22}\]
(Additionally, for any size classes below the recruitment size \(j < j_{min}\), we set all coefficients in the matrices \(A\), \(B\), \(C\) and vector \(S\) to \(0\) to avoid any dynamics in that range).
At the largest size (\(j=j_{max}\)): The size grid is truncated at \(w_{max}\), and the density above it is held at zero: \[ N_{j}^{t+1} = 0 \quad\text{for } j > j_{max}. \tag{23}\] Any flux that reaches the upper boundary \(w_{j_{max}+1}\) is simply lost — the boundary absorbs it rather than reflecting it back. One could interpret this as an infinite senescent mortality that removes every fish reaching \(w_{max}\), but a better approach is to choose \(w_{max}\) large enough that the flux reaching the boundary is already negligible: fish should grow to their asymptotic size and die of natural mortality well before \(w_{max}\), so the truncation has no material effect on the dynamics.
Note that \(w_{max}\) is distinct from \(w_{repro\_max}\), the size at which a typical mature individual diverts all available energy into reproduction. Somatic growth slows around \(w_{repro\_max}\), but not instantaneously — the maturity ogive is gradual, diffusion lets some individuals grow beyond it, and at \(w_{repro\_max}\) the growth rate need not vanish entirely. Choosing \(w_{max}\) sufficiently larger than \(w_{repro\_max}\) ensures that both the density and the flux have decayed to negligible levels before the boundary is reached.
The top retained class \(j_{max}\) depends on the scheme, because the two schemes place the advective inflow differently. With \(w_{max\_idx} = \max\{j : w_j \le
w_{max}\}\):
- the default first-order upwind scheme feeds class \(j\) from the growth of the class below, \(g(w_{j-1})\), so the class just above the one containing \(w_{max}\) can still carry advected density; here \(j_{max} = w_{max\_idx} + 1\). This reproduces the long-standing mizer behaviour exactly;
- the second-order scheme reconstructs the flux at a class’s own lower face, \(g(w_j)\), so its support ends one class lower, \(j_{max} = w_{max\_idx}\).
To impose Equation 23, the term \(C_{j_{max}}\) multiplying \(N_{j_{max}+1}^{t+1}\) is dropped (\(C_{j_{max}} = 0\)), exactly as at the lower boundary. This sets the back-substitution coefficient at \(j_{max}\) to zero, so the retained spectrum up to \(j_{max}\) is solved independently of the classes above it; those classes are then set to zero after the tridiagonal solve. The coefficients \(A_{j_{max}}\) and \(B_{j_{max}}\) use the standard formulas; in particular \(B_{j_{max}}\) keeps its advective outflow term, which carries whatever (possibly non-zero) growth flux leaves the grid at the truncation boundary.
Without diffusion the truncation reproduces the untruncated mizer behaviour: the classes above \(j_{max}\) receive no advective inflow once \(w_{max}\) is past the size where growth has died away, so they are already zero and imposing Equation 23 changes nothing. With diffusion, density would otherwise leak to sizes above \(w_{max}\); the boundary condition holds it at zero there instead. Because the location of \(j_{max}\) is fixed by \(w_{max}\) and the scheme — not by the densities — it is the same at every time step and at the steady state.
Numerical Diffusion
The upwind scheme used for the advective term introduces numerical diffusion. This is a well-known property of first-order upwind schemes. We can estimate the magnitude of this diffusion by expanding the discretised term using a Taylor series.
The discretised equation for the transport (advection only, with constant rates for simplicity) is: \[ \frac{N_j^{t+1} - N_j^t}{\Delta t} + g \frac{N_j^{t+1} - N_{j-1}^{t+1}}{\Delta w} = 0 \tag{24}\] Expanding \(N(w, t)\) around \((w_j, t+\Delta t)\) leads to the following leading order error terms: \[ \frac{\partial N}{\partial t} + g \frac{\partial N}{\partial w} = \frac{g \Delta w}{2} \left( 1 + \frac{g \Delta t}{\Delta w} \right) \frac{\partial^2 N}{\partial w^2} \tag{25}\] The coefficient of the second derivative represents the numerical diffusivity: \[ D_{num} = \frac{g \Delta w}{2} (1 + C) \tag{26}\] where \(C = \frac{g \Delta t}{\Delta w}\) is the Courant-Friedrichs-Lewy (CFL) number. Comparing this to the Mizer diffusion equation form (where the diffusion term is \(\frac{\partial}{\partial w} ( \frac{1}{2} \frac{\partial (D N)}{\partial w} )\)), the effective diffusion parameter is: \[ d_{num}(w) \approx g(w) \Delta w (1 + C(w)) \tag{27}\] Since \(\Delta w \approx w \ln(\beta)\), this is: \[ d_{num}(w) \approx g(w) w \ln(\beta) \left( 1 + \frac{g(w) \Delta t}{w \ln(\beta)} \right) = g(w) w \ln(\beta) + g(w)^2 \Delta t \tag{28}\] This means the numerical scheme behaves as if there is a diffusion \(d_{num}\). This numerical diffusion has two components: one from spatial discretisation (scaling with \(\Delta w\)) and one from time stepping (scaling with \(\Delta t\)).
Order of Accuracy
The scheme is first order in time. To see this, expand the backward difference around the new time level: \[
\frac{N_j^{t+1} - N_j^t}{\Delta t}
= \frac{\partial N_j}{\partial t}(t+\Delta t)
- \frac{\Delta t}{2}\frac{\partial^2 N_j}{\partial t^2}(t+\Delta t)
+ O(\Delta t^2).
\tag{29}\] Thus the time discretisation has a truncation error of order \(O(\Delta t)\). Evaluating the rates \(g\), \(d\) and \(\mu\) at time \(t\) instead of \(t+1\) also introduces only an \(O(\Delta t)\) error, provided the rates vary smoothly in time. The semi-implicit scheme is therefore first order in \(\Delta t\).
For the spatial discretisation, the upwind advective flux is the limiting term. For smooth \(gN\), \[
\frac{(gN)_j - (gN)_{j-1}}{\Delta w_{j-1}}
= \frac{\partial(gN)}{\partial w}(w_j)
- \frac{\Delta w_{j-1}}{2}\frac{\partial^2(gN)}{\partial w^2}(w_j)
+ O(\Delta w_{j-1}^2),
\tag{30}\] so the upwind advective reconstruction has an \(O(\Delta w_j)\) spatial truncation error. The diffusive flux, being a central difference of the bin-averaged products between bin centres (Equation 10), is second order, and the bin-averaged sinks are second order too; so on the default scheme the spatial order is set entirely by the upwind advective reconstruction. Replacing it by a higher-order reconstruction (Section 13) removes this last \(O(\Delta w_j)\) error.
On the logarithmic grid, writing \(\beta = w_{j+1}/w_j\), we have \[
\Delta w_j = w_j(\beta - 1) = w_j\left(\log\beta + O((\log\beta)^2)\right).
\tag{31}\] Thus, at fixed body size \(w_j\), first order in \(\Delta w_j\) is equivalently first order in \(\log\beta\). Combining the time and space errors, the scheme is \[
O(\Delta t) + O(\Delta w_j)
\tag{32}\] locally, or \(O(\Delta t + \log\beta)\) on the logarithmic grid.
Predictor-Corrector Time Stepping
A straightforward way to make the time discretisation second order is to combine a predictor step for the rates with a Crank-Nicolson corrector for the densities. The aim is to keep the useful property that, once the rates are fixed, the density update is still a tridiagonal linear solve.
Let \(L(r)\) denote the spatial operator for the consumer spectrum when the rates \[
r = (g, d, \mu)
\tag{33}\] are fixed, and let \(q(R_{dd})\) denote the recruitment source at the lower boundary. The semi-implicit Euler method used above can be written schematically as \[
\frac{N^{t+1} - N^t}{\Delta t} = L(r^t) N^{t+1} + q(R_{dd}^t).
\tag{34}\] This is first order because the rates and recruitment are only evaluated at the start of the time step.
The predictor-corrector method proceeds as follows:
-
Predict: Use the existing semi-implicit Euler scheme with rates \(r^t\) to get a provisional value \(\hat{N}^{t+1}\).
-
Recalculate rates: Evaluate provisional end-of-step rates \(\hat{r}^{t+1}\) and recruitment \(\hat{R}_{dd}^{t+1}\) from \(\hat{N}^{t+1}\).
-
Approximate midpoint rates: Use \[
r^{t+1/2} = \frac{1}{2}\left(r^t + \hat{r}^{t+1}\right),
\tag{35}\] so in particular \[
g_j^{t+1/2} = \frac{1}{2}\left(g_j^t + \hat{g}_j^{t+1}\right), \quad
d_j^{t+1/2} = \frac{1}{2}\left(d_j^t + \hat{d}_j^{t+1}\right), \quad
\mu_j^{t+1/2} = \frac{1}{2}\left(\mu_j^t + \hat{\mu}_j^{t+1}\right).
\tag{36}\] The recruitment flux is averaged in the same way: \[
R_{dd}^{t+1/2} = \frac{1}{2}\left(R_{dd}^t + \hat{R}_{dd}^{t+1}\right).
\tag{37}\]
-
Correct: Do a Crank-Nicolson update using the midpoint rates: \[
\frac{N^{t+1} - N^t}{\Delta t}
= \frac{1}{2}\left(L(r^{t+1/2})N^t + L(r^{t+1/2})N^{t+1}\right)
+ q(R_{dd}^{t+1/2}).
\tag{38}\]
In flux form, the corrector equation for an interior bin is \[
\begin{aligned}
\frac{N_j^{t+1} - N_j^t}{\Delta t}
&+ \frac{1}{2\Delta w_j}
\left[
\left(J_{j+1}^{t+1} - J_j^{t+1}\right)
+ \left(J_{j+1}^t - J_j^t\right)
\right] \\
&= -\frac{1}{2}\mu_j^{t+1/2}\left(N_j^{t+1} + N_j^t\right),
\end{aligned}
\tag{39}\] where all fluxes use the midpoint rates. For example, \[
J_j^{t+1}
= g_j^{t+1/2} N_{j-1}^{t+1}
- \frac{1}{2}\frac{
d_j^{t+1/2} N_j^{t+1}
- d_{j-1}^{t+1/2} N_{j-1}^{t+1}
}{\Delta w_{j-1}^c},
\tag{40}\] and \(J_j^t\) is the same expression with \(N^t\) instead of \(N^{t+1}\). The lower boundary uses \[
J_{j_{min}}^{t+1} = J_{j_{min}}^t = R_{dd}^{t+1/2}.
\tag{41}\]
Because the midpoint rates are fixed during the corrector step, the unknowns still enter only through \(N_{j-1}^{t+1}\), \(N_j^{t+1}\) and \(N_{j+1}^{t+1}\). The corrector is therefore again a tridiagonal system. The difference from the first-order scheme is that the old-time fluxes and mortality terms are moved to the right-hand side, while the new-time terms supply the tridiagonal matrix.
If the provisional predictor has the usual one-step accuracy, the averaged rates approximate the true midpoint rates to second order. The Crank-Nicolson corrector is then second order in \(\Delta t\) for smooth solutions: \[
\text{time error} = O(\Delta t^2).
\tag{42}\] This does not change the spatial order of the scheme, which remains first order because of the upwind advective flux. The combined order would therefore be \[
O(\Delta t^2) + O(\Delta w_j),
\tag{43}\] or \(O(\Delta t^2 + \log\beta)\) on the logarithmic grid.
There are two practical cautions. First, this doubles the number of rate evaluations per time step. Second, Crank-Nicolson-type methods are less damping than backward Euler, so for large time steps they can show oscillations even when they are formally stable. Positivity and robustness would therefore need to be checked carefully before using this as the default time stepper.
TR-BDF2 Time Stepping
The oscillations of the Crank-Nicolson corrector are a consequence of its stability function. For the scalar test problem \(N' = \lambda N\) the corrector multiplies the solution by \[
R_{CN}(z) = \frac{1 + z/2}{1 - z/2}, \qquad z = \lambda\,\Delta t,
\tag{44}\] and for a strongly damped mode (\(\lambda\) real and very negative) \(R_{CN}(z) \to -1\) as \(z \to -\infty\). Such modes are therefore barely damped and flip sign every step. This is the ringing seen at large \(\Delta t\), and it is driven most strongly by the non-smooth recruitment boundary at \(w_{min}\). Crank-Nicolson is A-stable but not L-stable: it does not satisfy \(R(z) \to 0\) as \(z \to -\infty\).
The TR-BDF2 method, selected with method = "tr_bdf2", keeps second-order accuracy but is L-stable, so the stiff modes are damped rather than ringing. It is a one-step, two-stage method. Writing the frozen-rate spatial operator and recruitment source as \(L\) and \(q\) (as above), and using a stage fraction \(\gamma\), one step from \(N^t\) to \(N^{t+1}\) is
-
Trapezoidal (TR) stage over \([t, t+\gamma\Delta t]\): \[
\frac{N^{t+\gamma} - N^t}{\gamma\Delta t}
= \tfrac{1}{2}\left(L N^t + L N^{t+\gamma}\right) + q.
\tag{45}\]
-
Backward-differentiation (BDF2) stage over the whole step, using \(N^t\), \(N^{t+\gamma}\) and \(N^{t+1}\): \[
N^{t+1} = \frac{1}{\gamma(2-\gamma)}N^{t+\gamma}
- \frac{(1-\gamma)^2}{\gamma(2-\gamma)}N^t
+ \frac{1-\gamma}{2-\gamma}\,\Delta t\left(L N^{t+1} + q\right).
\tag{46}\]
The standard choice is \[
\gamma = 2 - \sqrt{2},
\tag{47}\] which makes the method L-stable and, crucially for the implementation, makes the two stages share the same implicit coefficient. The TR stage implicitly multiplies \(L\) by \(\gamma\Delta t/2\) and the BDF2 stage by \((1-\gamma)/(2-\gamma)\,\Delta t\), and for \(\gamma = 2-\sqrt 2\) both equal \[
\alpha\,\Delta t, \qquad \alpha = \frac{\gamma}{2} = 1 - \frac{1}{\sqrt 2}.
\tag{48}\] Each stage is therefore a solve against the same matrix \(I - \alpha\Delta t\,L\), which is exactly the tridiagonal operator \(\tt{get\_transport\_coefs()}\) builds at time step \(\alpha\Delta t\). The matrix is assembled once and the BDF2 stage reuses it; only the right-hand sides differ. Writing \(c_1 = (\sqrt 2 + 1)/2\) and \(c_0 = (\sqrt 2 - 1)/2\) (with \(c_1 - c_0 = 1\)), the right-hand sides are \[
\begin{aligned}
S^{TR} &= 2N^t - (I - \alpha\Delta t\,L)\,N^t + \gamma\Delta t\, q, \\
S^{BDF2} &= c_1 N^{t+\gamma} - c_0 N^t + \alpha\Delta t\, q.
\end{aligned}
\tag{49}\] The first of these is the Crank-Nicolson right-hand side over the sub-step \(\gamma\Delta t\), so the TR stage reuses the existing corrector assembly.
The nonlinear rates are treated exactly as in the predictor-corrector method: a provisional Euler predictor gives end-of-step rates, these are averaged with the start-of-step rates to obtain second-order midpoint rates, and the frozen operator \(L\) uses those midpoint rates. The result is second order in \(\Delta t\) for the full nonlinear dynamics while remaining L-stable, at the cost of one predictor solve, two stage solves and one rate recalculation per step.
At a steady state the argument of the previous section applies unchanged: with \(N^t = N^{t+\gamma} = N^{t+1} = N^*\) both stages reduce to \(L N^* + q = 0\). TR-BDF2 therefore has the same fixed point as the Euler and predictor-corrector methods and only changes the transient path.
Accuracy comparison
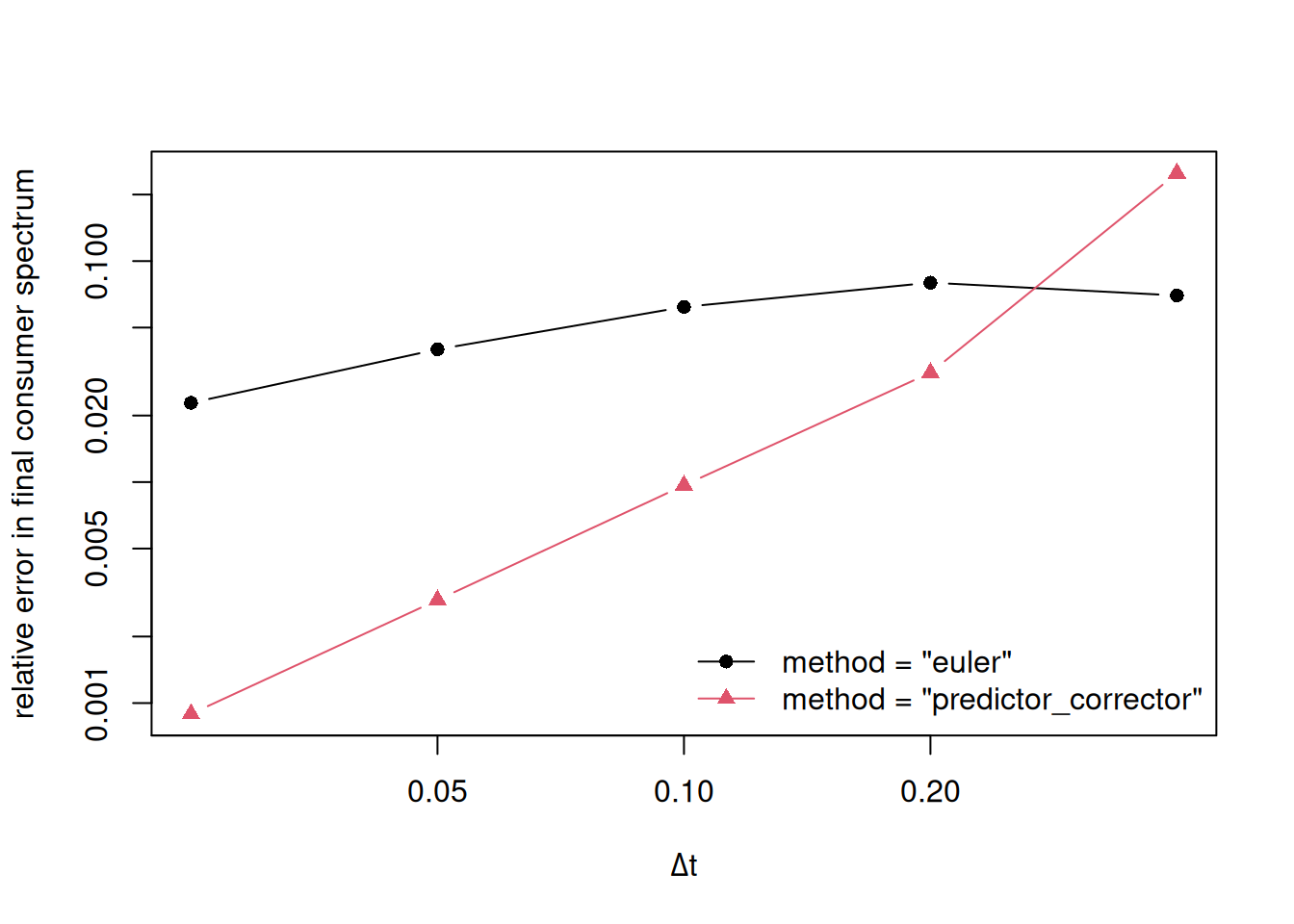
This vignette compares the first-order consumer density update, selected with method = "euler", with the two second-order updates selected with method = "predictor_corrector" and method = "tr_bdf2", on the North Sea example model NS_params.
The comparison is intentionally modest. It is meant as a reproducible smoke test for speed and time-step sensitivity, not as a comprehensive benchmark.
We compare final consumer spectra against a smaller-time-step reference solution from the TR-BDF2 method. Because all methods use the same spatial discretisation, this test is only about the time discretisation error on the fixed NS_params weight grid.
Code
t_max <- 8
dt_values <- c(1.6, 0.8,0.4, 0.2, 0.1, 0.05, 0.025)
reference_dt <- 0.4 / 2^6
params <- NS_params
initial_effort(params) <- 4
relative_l2_error <- function(x, reference) {
x_final <- finalN(x)
reference_final <- finalN(reference)
sqrt(sum((x_final - reference_final)^2)) / sqrt(sum(reference_final^2))
}
reference <- project(
params,
dt = reference_dt,
t_max = t_max,
method = "tr_bdf2"
)
accuracy <- do.call(rbind, lapply(dt_values, function(dt) {
euler <- project(params, dt = dt, t_max = t_max, t_save = t_max,
method = "euler")
pc <- project(params, dt = dt, t_max = t_max, t_save = t_max,
method = "predictor_corrector")
trbdf2 <- project(params, dt = dt, t_max = t_max, t_save = t_max,
method = "tr_bdf2")
data.frame(
dt = dt,
euler_error = relative_l2_error(euler, reference),
predictor_corrector_error = relative_l2_error(pc, reference),
tr_bdf2_error = relative_l2_error(trbdf2, reference)
)
}))
accuracy
dt euler_error predictor_corrector_error tr_bdf2_error
1 1.600 0.31596647 3.4780282823 0.1485219020
2 0.800 0.15030919 1.5930749272 0.2161710472
3 0.400 0.06998422 0.2491341164 0.0858144631
4 0.200 0.07996242 0.0305651825 0.0305334237
5 0.100 0.06213206 0.0089017443 0.0091873340
6 0.050 0.03998051 0.0023680430 0.0024242194
7 0.025 0.02294875 0.0005722933 0.0005797011
Code
plot(
euler_error ~ dt,
data = accuracy,
log = "xy",
type = "b",
pch = 16,
xlab = expression(Delta * t),
ylab = "relative error in final consumer spectrum",
ylim = range(accuracy$euler_error, accuracy$predictor_corrector_error,
accuracy$tr_bdf2_error)
)
lines(
predictor_corrector_error ~ dt,
data = accuracy,
type = "b",
pch = 17,
col = 2
)
lines(
tr_bdf2_error ~ dt,
data = accuracy,
type = "b",
pch = 15,
col = 4
)
legend(
"bottomright",
legend = c('method = "euler"', 'method = "predictor_corrector"',
'method = "tr_bdf2"'),
pch = c(16, 17, 15),
col = c(1, 2, 4),
lty = 1,
bty = "n"
)
Speed
The second-order methods do roughly twice the work per time step. The predictor-corrector method performs one predictor solve and then recalculates the rates before doing the corrector solve. TR-BDF2 performs the same predictor solve and rate recalculation, and then two stage solves against the shared operator, so it is marginally more expensive than the predictor-corrector method per step.
The resource update
Under the second-order methods the resource is also advanced to second order. The resource mortality \(\mu_R\) depends on the consumer densities, so evaluating it only at the start of the step would make the resource update first order and cap the overall accuracy. Instead, the predictor step is used to form the same midpoint rates \(r^{t+1/2}\) that drive the consumer corrector, and the resource is then advanced with the midpoint resource mortality \[
\mu_R^{t+1/2} = \tfrac{1}{2}\left(\mu_R^t + \hat\mu_R^{t+1}\right).
\tag{50}\] At a steady state \(r^t = \hat r^{t+1} = r^{t+1/2}\), so the resource corrector reproduces the predictor and the steady state is unchanged. With the default semi-chemostat resource dynamics, which already use the analytic solution for fixed mortality, the remaining resource error is small, but the midpoint mortality removes the first-order time-stepping component. The euler method keeps the first-order resource update.
Interpretation
On short runs the second-order methods may not always show a clean second-order convergence slope because the comparison is affected by the fixed spatial grid, nonlinear rate feedbacks and ordinary timing noise. TR-BDF2 typically shows the cleanest slope of the three because, being L-stable, it does not ring at the larger time steps.
Because the predictor-corrector method is more expensive per time step, the relevant comparison is between the Euler method at a given dt and the predictor-corrector method at twice the dt so that both have similar run times.
Numerical Diffusion for the Predictor-Corrector Method
The predictor-corrector method uses the same upwind approximation in size as the first-order method, so it still has numerical diffusion. However, the Crank-Nicolson corrector changes the time-stepping contribution to that diffusion.
To see this, again consider the advection-only problem with constant growth rate \(g\) on a locally uniform grid with spacing \(\Delta w\): \[
\frac{\partial N}{\partial t} + g\frac{\partial N}{\partial w} = 0.
\tag{51}\] With fixed rates, the corrector step reduces to the Crank-Nicolson upwind scheme \[
\frac{N_j^{t+1} - N_j^t}{\Delta t}
+ \frac{g}{2}
\left[
\frac{N_j^{t+1} - N_{j-1}^{t+1}}{\Delta w}
+ \frac{N_j^t - N_{j-1}^t}{\Delta w}
\right] = 0.
\tag{52}\]
Expand this equation about the midpoint \((w_j, t + \Delta t / 2)\). The centred time difference gives \[
\frac{N_j^{t+1} - N_j^t}{\Delta t}
= \frac{\partial N}{\partial t}
+ O(\Delta t^2).
\tag{53}\] The average of the two upwind spatial differences gives \[
\frac{1}{2}
\left[
\frac{N_j^{t+1} - N_{j-1}^{t+1}}{\Delta w}
+ \frac{N_j^t - N_{j-1}^t}{\Delta w}
\right]
= \frac{\partial N}{\partial w}
- \frac{\Delta w}{2}\frac{\partial^2 N}{\partial w^2}
+ O(\Delta w^2) + O(\Delta t^2).
\tag{54}\] Substituting these expansions into the scheme gives the modified equation \[
\frac{\partial N}{\partial t} + g\frac{\partial N}{\partial w}
= \frac{g\Delta w}{2}\frac{\partial^2 N}{\partial w^2}
+ O(\Delta w^2) + O(\Delta t^2).
\tag{55}\] Thus the numerical diffusivity in the usual advection-diffusion form is \[
D_{num}^{PC} = \frac{g\Delta w}{2}.
\tag{56}\] In the mizer notation, where the diffusion term is written with a factor \(1/2\) inside the flux, this corresponds to the effective diffusion parameter \[
d_{num}^{PC}(w) \approx g(w)\Delta w.
\tag{57}\] On the logarithmic grid this becomes \[
d_{num}^{PC}(w) \approx g(w)w\log\beta.
\tag{58}\]
Compared with the first-order semi-implicit scheme, \[
d_{num}^{Euler}(w) \approx g(w)\Delta w + g(w)^2\Delta t,
\tag{59}\] the predictor-corrector method removes the leading artificial diffusion proportional to \(\Delta t\). The remaining numerical diffusion is the spatial upwind diffusion, proportional to \(\Delta w\) or equivalently to \(\log\beta\) on the logarithmic grid. This is why decreasing \(\Delta t\) eventually stops improving the error much: once the time-stepping error is small, the spatial upwind error and other fixed discretisation errors dominate.
Reducing the Spatial Error: a Higher-Order Reconstruction
In the scheme above only one ingredient is first order: the upwind reconstruction of the boundary density in the advective flux (Equation 9). Using the bin-below average \(N_{j-1}\) as the density at the boundary \(w_j\) introduces the numerical diffusion \(d_{num}\approx g(w)\,w\log\beta\) derived earlier, and on a coarse logarithmic grid (a few hundred bins over many decades) it is not small. It is the one spatial error the second-order time methods cannot remove. The flux entry of the second_order_w slot replaces the upwind reconstruction by a higher-order one. Because the choice changes the discrete steady state it lives in the params object rather than being a project() argument.
The reconstruction
The boundary \(w_j\) is the midpoint, on the logarithmic axis, of the two bin centres \(w_{j-1}^c\) and \(w_j^c\), so a second-order estimate of the density there is the average of the two bin averages. We write the general reconstruction with a weight \(\chi_j\), \[ N(w_j) \approx N_{j-1} + \tfrac12\,\chi_j\,(N_j - N_{j-1}), \tag{60}\] which is pure upwind (\(N_{j-1}\)) when \(\chi_j = 0\) and the centred value \(\tfrac12(N_{j-1}+N_j)\) when \(\chi_j = 1\). The advective flux becomes \[ J_j^{adv} = g_j\bigl[N_{j-1} + \tfrac12\,\chi_j(N_j - N_{j-1})\bigr]. \tag{61}\] With \(\chi_j = 1\) the upwind numerical diffusion is gone and the advective flux is second order. The remaining requirement for a fully second-order model is that the bin-average rates — the diffusion coefficient \(d_j\) in the diffusive flux (Equation 10) and the mortality \(\mu_j\) in the sink (Equation 14) — actually be bin-averaged rather than point-sampled. That is the job of the bin_average entry of the slot, which gates exactly that point-versus-bin-average choice for \(d\) and \(\mu\) alike.
Choosing the weight: van Leer or centred
With \(\chi\equiv1\) the reconstruction is the pure centred one, which is genuinely second order everywhere, including at smooth extrema, but is not monotonicity-preserving: it can produce small over/undershoots, and at a steady state with no physical diffusion it admits an undamped odd-even mode. With the van Leer weight \[
\chi_j=\chi(r_j),\qquad
\chi(r)=\frac{r+|r|}{1+|r|},\qquad
r_j=\frac{N_{j-1}-N_{j-2}}{N_j-N_{j-1}},
\tag{62}\] the scheme is total-variation diminishing (TVD): \(\chi\to1\) where the solution is smooth, and \(\chi\to0\) (pure upwind) at extrema and at the non-smooth recruitment boundary. This keeps abundances non-negative and manufactures no new oscillations, at the price — a corollary of Godunov’s theorem — of dropping to first order at smooth extrema.
At the left boundary of the grid where \(N_{j-2}\) does not exist, the weight is handled as follows:
- At and below the first two faces above the recruitment boundary (\(j \le j_{min} + 2\)), the weight \(\chi_j\) is forced to 0. This keeps the advective flux leaving the recruitment boundary first-order upwind and avoids referencing the non-smooth recruitment boundary cell \(N_{j_{min}}\) (and the inactive region below it) when calculating the smoothness ratio, preventing ragged or oscillating solutions near the boundary.
The two types are selected with
The default (TRUE) is van Leer, the safe choice for production runs; the centred reconstruction is most useful for smooth problems that carry some physical diffusion.
Implicit treatment with a frozen weight
The weight \(\chi_j\) is evaluated from the densities at the start of the step (for the second-order methods, from the midpoint field), so it is a fixed number during the solve. With \(\chi\) frozen, the flux Equation 61 is linear in the unknown densities \(N^{t+1}\) and still couples only \(N_{j-1},N_j,N_{j+1}\), so it folds directly into the same tridiagonal operator \(\tt{get\_transport\_coefs()}\) builds — only the advective coefficients gain the \(\chi\) terms. Keeping the high-order term implicit in this way is important: treating the extra (anti-diffusive) part explicitly on the right-hand side is only conditionally stable and breaks down for the lightly damped second-order time steppers, whereas the implicit form is stable for backward Euler and TR-BDF2 even with no physical diffusion.
The price is that the high-order term can make the off-diagonal coefficient \(C_j\) positive, so the operator is no longer an M-matrix and non-negativity is no longer guaranteed by construction. The van Leer reconstruction keeps any undershoot at the level of rounding, and the consumer update floors it to zero to preserve \(N\ge 0\); the unlimited centred reconstruction gives up this guarantee in exchange for the extra order.
Because the reconstruction weight is frozen at the beginning (or midpoint) of the step, the flux limiter is only conditionally total-variation diminishing (TVD). In simulations with highly dynamic, sharp features (such as pulsed reproduction starting from a zero initial abundance), the time step \(\Delta t\) must satisfy the Courant-Friedrichs-Lewy (CFL) condition, which requires that the log-size Courant number \[ C = \frac{g(w) \Delta t}{w \log\beta} \] be at most \(1\) across the grid. If the Courant number exceeds 1, the lagged limiter can no longer guarantee the TVD property, resulting in spurious oscillations (wiggles) and negative densities (which the update floors to zero, leading to a ragged/zero-interleaved distribution). To avoid wiggles in such cases, users should either reduce dt so that \(C \le 1\), or use the first-order upwind scheme (by setting second_order_w(params) <- FALSE and using the L-stable method = "tr_bdf2") which remains positive and monotonic for any dt.
Steady state and reproduction
Because the reconstruction lives entirely in the coefficients \(A,B,C\), the steady-state machinery stays consistent automatically: getRequiredRDD() reads the same boundary coefficients and get_steady_state_n() solves the same system. With the van Leer reconstruction the weight depends on the solution, so the steady state is found by an under-relaxed fixed-point iteration (freezing \(\chi\) at the current iterate, solving, repeating), because at \(\Delta t=1\) the operator is not diagonally dominant. Both getRequiredRDD() and steadySingleSpecies() read the same second_order_w slot, so a model is automatically set up at the steady state of exactly the scheme that project() will use, and that state is preserved to machine precision by all three time-stepping methods.
Steady-State Solution
When solving the steady-state ODE instead of the time-dependent PDE, we are looking for a state where the population densities do not change over time, meaning \(N_j^{t+1} = N_j^t = N_j^*\).
Substituting this into our discretised linear system: \[
A_j N_{j-1}^* + B_j N_j^* + C_j N_{j+1}^* = S_j
\tag{63}\] Recall that for \(j > j_{min}\), \(S_j = N_j^t\). The equation simplifies to: \[
A_j N_{j-1}^* + (B_j - 1) N_j^* + C_j N_{j+1}^* = 0
\tag{64}\]
To find the steady-state population densities \(N^*\), we formulate a new time-independent tridiagonal system: \[
\tilde{A}_j N_{j-1}^* + \tilde{B}_j N_j^* + \tilde{C}_j N_{j+1}^* = \tilde{S}_j
\tag{65}\] To eliminate the explicit dependence on the time step \(\Delta t\), we can divide the equation by \(\Delta t\). The modified coefficients \(\tilde{A}, \tilde{B}, \tilde{C}\) defining the new tri-diagonal system are: \[
\begin{aligned}
\tilde{A}_j &= \frac{A_j}{\Delta t} = -\frac{1}{\Delta w_j} \left( g_j + \frac{1}{2} \frac{d_{j-1}}{\Delta w_{j-1}^c} \right) \\
\tilde{C}_j &= \frac{C_j}{\Delta t} = -\frac{1}{\Delta w_j} \left( \frac{1}{2} \frac{d_{j+1}}{\Delta w_j^c} \right) \\
\tilde{B}_j &= \frac{B_j - 1}{\Delta t} = \mu_j + \frac{1}{\Delta w_j} \left( g_{j+1} + \frac{1}{2} \frac{d_j}{\Delta w_j^c} + \frac{1}{2} \frac{d_j}{\Delta w_{j-1}^c} \right)
\end{aligned}
\tag{66}\] Notice that \(\tilde{A}_j\) and \(\tilde{C}_j\) are exactly the expressions for \(A_j\) and \(C_j\) evaluated at \(\Delta t = 1\). Similarly, \(\tilde{B}_j\) is exactly the expression for \(B_j - 1\) evaluated at \(\Delta t = 1\).
Boundary conditions for the steady state:
For the smallest size (\(j=j_{min}\)), the original equation had a source term due to recruitment: \[
S_{j_{min}} = N_{j_{min}}^t + \frac{\Delta t}{\Delta w_{j_{min}}} R_{dd}
\tag{67}\] Following the same logic of setting \(N^{t+1} = N^t = N^*\) and dividing by \(\Delta t\), the right-hand side vector \(\tilde{S}_j\) for the steady-state system becomes purely the recruitment flux term. If we again observe the original term \(\frac{\Delta t}{\Delta w_{j_{min}}} R_{dd}\) when evaluated at \(\Delta t = 1\), we get our new source vector: \[
\tilde{S}_{j_{min}} = \frac{R_{dd}}{\Delta w_{j_{min}}}
\tag{68}\] For all other \(j > j_{min}\), \(\tilde{S}_j = 0\).
The boundary condition modifications at the edges of the grid remain the same conceptually: \(\tilde{A}_{j_{min}} = 0\), the upward diffusion term is omitted from \(\tilde{B}_{j_{min}}\), and \(\tilde{C}_{j_{max}} = 0\), where \(j_{max}\) is the support top of the previous section (the first class above \(w_{max}\)). The density is held at zero for any \(j < j_{min}\) or \(j > j_{max}\).
In code, this means that the steady-state coefficients for the matrix multiplication (\(\tilde{A}, \tilde{B}, \tilde{C}\)) and the constant vector (\(\tilde{S}\)) can be calculated by calling the standard coefficient function but simply setting \(\Delta t = 1\), and dropping the \(+1\) and \(+N_j^t\) from the resulting \(B\) and \(S\) variables respectively.
With these modified matrices, the steady-state densities can be calculated directly by solving the linear system avoiding the need to iterate step by step over time.
Steady-State Solution for the Predictor-Corrector Method
The predictor-corrector method changes the time stepping, but it does not change the steady state that is obtained when the rates are evaluated at that steady state. To see this, write the Crank-Nicolson corrector with fixed midpoint rates as \[
\frac{N^{t+1} - N^t}{\Delta t}
= \frac{1}{2}\left(L N^t + L N^{t+1}\right) + q,
\tag{69}\] where \(L\) is the spatial transport-and-mortality operator built from the midpoint rates and \(q\) is the recruitment source at the lower boundary. At a steady state, \(N^{t+1} = N^t = N^*\), so this becomes simply \[
0 = L N^* + q.
\tag{70}\]
Thus the predictor-corrector method has the same fixed-point equation as the first-order method. The predictor step also becomes irrelevant at the fixed point: if \(N^t = N^*\), then the predicted \(\hat{N}^{t+1}\) is also \(N^*\) up to the residual of the steady-state equation, so \[
r^t = \hat{r}^{t+1} = r^{t+1/2}, \qquad
R_{dd}^t = \hat{R}_{dd}^{t+1} = R_{dd}^{t+1/2}.
\tag{71}\] The rates used in the steady-state calculation are therefore just the rates evaluated at \(N^*\). The predictor-corrector method affects the transient path to the steady state, not the steady state itself.